newsql
这篇文章主要整理了比如 tidb 这种 newsql 是如何用 rocksdb 支撑的,并根据 rocksdb 的特性分析他适合支撑的业务特性。
rocksdb的特性
首先总结一下 rocksdb的特性。
详细文章可以参考文档1,以下仅为总结
- rocksdb 只提供最基础的kv 操作
- rocksdb 底层基于leveldb,所以每个ssfile 都是按照key
顺序排序的。
2.1 所以, 在rocksdb 检索一个key的时间复杂度为 O(lgn) (二分查找)
2.2 所以, 在rocksdb 中进行迭代操作(e.g scan)成本很低 - rocksdb 每一个 ssfile 都带一个 bloomfilter 用来快速定位key是否存在本ssfile
3.1 由于blooomfilter的存在,check 一个ssfile 是否存在key 的时间复杂度为O(1) - rocksdb 由于level 的关系,越老的数据会存在越level 越大的ssfile中。检索速度会被放大。
4.1 所以,很多时序数据库以rocksdb 作为底层存储,他的业务特性和rocksdb 非常契合。
4.2 所以,有些数据是随着时间增长而增长,但查询时却需要全量过滤的数据,用rocksdb查询,其效率会随着时间区间的增长而降低。
tidb 中 sql 2 kv 的转换
首先,tidb 在上层提供了sql查询的支持,底层则用只支持 kv 操作的rocksdb做实际存储。
以下则是实际存储的方案。
对于一张table e.g
1 | CREATE TABLE User { |
需要存储的数据包括三部分:
- 表的元信息
- Table 中的 Row
- 索引数据
TiDB 对每个表分配一个 TableID,每一个索引都会分配一个 IndexID,每一行分配一个 RowID(如果表有整数型的 Primary Key,那么会用 Primary Key 的值当做 RowID),其中 TableID 在整个集群内唯一,IndexID/RowID 在表内唯一,这些 ID 都是 int64 类型。
每行数据按照如下规则进行编码成 Key-Value pair:
1 | Key: tablePrefix{tableID}_recordPrefixSep{rowID} |
注意:以上相当于是mysql 的聚集索引。可以通过聚集索引快速定位到一行数据
对于 uniq index ,会按照如下规则编码成 Key-Value pair:
1 | Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue |
对于 非 uniq index(因为可能会重复),会按照如下规则编码成 Key-Value pair:
1 | Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue_rowID |
在tikv中,实际的prefix 如下
1 | var( |
假设 tableID 为 1
最终存储方式如下图所示
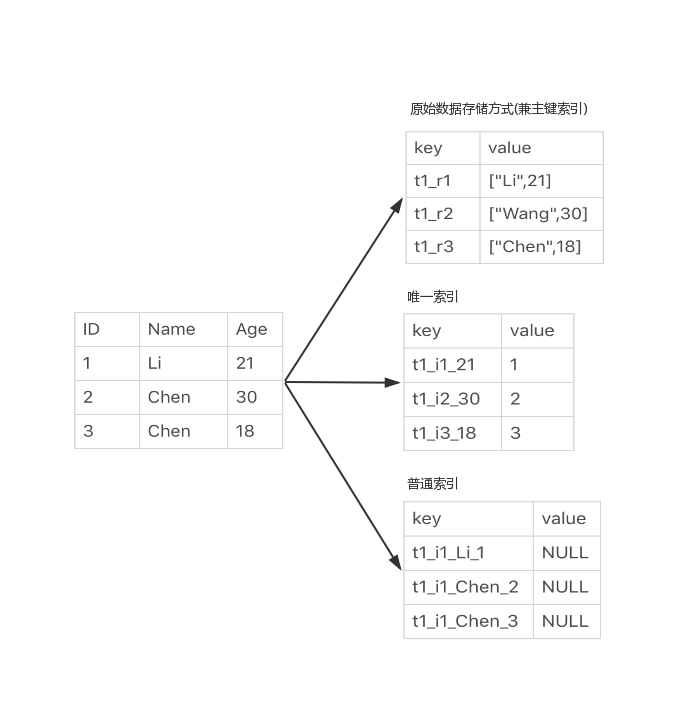
由上图可猜想。
- tidb 对于没有建索引的数据,查询速度是极慢的,因为需要遍历整张表。
滴滴的 sql 2 redis 的转换
原文在参考文档2,这里简述一下。
滴滴自己做了一套类似tidb 的 newSql,架构上的区别就是,将tidb 的 rift 干掉了。
还有就是,他底层不是直接基于 rocksdb, 而是基于 redis 的数据结构搞得(底层其实还是rocksdb)。
这里我们先看一下他的sql 2 kv 的设计
完整数据的存储,兼聚集索引
索引的结构和 tidb 一模一样, 直接用kv存储
唯一索引:
1 | Key: |
非唯一索引:
1 | Key: |
索引查询方式,文章说是根据 scan 查询,根据rocksdb 的api,大概率是直接 iterator。
然后我们再来看下hashmap的实际实现,这里我们可以参考pika的实现
一个hash 其实由多个kv 组成
然后,每一个field, value 对应了 rocksdb 的 一对kv
那滴滴这个全量数据为啥要用hash的方式,而不是类似 tidb 的kv方式呢?
个人感觉是参考率列式存储的概念,减少查询不必要的字段,减少因大value导致的内存抖动。
总结
由于目前newsql的底层一般都用的rocksdb。而rocksdb本质上还是按level划分的。
所以很显然,现在的newsql将会受到时间的影响。如果数据存入的时间跨度越大,然后业务查询时却又需要查询类似大跨度的范围时,查询效率显然会很低。
上面总结了最近调研的 newsql 到kv 的转换过程,我们实际业务场景在选型是否引入类似tidb的时候,可以先考虑一下自己的业务场景,评估一下 newsql 是否会提升性能,再作决定。
参考文档

lelouchcr's blog